본 글은 Operating System Concepts 10판을 기준으로 작성되었습니다...!
"시험공부하면서 작성중"

Program: 디스크에 존재하는 실행 가능한 파일 (.exe), 메모리에 로드되면 프로세스가 된다. 정적입니다.
Process: 프로그램이 실행된 상태. 스레드 이전에는 스케줄링의 기본 단위였다. 커널이 process ID(PID)를 통해 프로세스를 관리한다. (Table 이용) 프로그램을 실행하게 되면 프로그램의 복사판인 프로세스를 만들어 메모리에 올리는 것. 동적인 존재입니다.

Text (code): 실행할 코드의 모음
Data: 전역 변수들
Heap: 프로그램 실행 시 동적으로 할당되는 메모리
Stack: 함수 수행을 위해 사용되는 임시 저장소, 함수가 실행되면 데이터가 쌓였다가, 리턴하면 사라짐

new : 프로세스의 생성, 로드하고, 초기화 작업하고, PID부여받고 등등...
running : 프로세스가 실행중인 상태. ready에서 스케줄러에 의해 코어를 할당받으면 (dispatch) running.
ready : 새로운 프로세서에 할당되기를 기다리는 상태, 지금 당장 CPU에 올라가 일을 수행해도 되는 상태. waiting 상태인 다른 프로세스가 요청한 I/O가 완료되어 interrupt가 걸리면 running에서 ready로 온다. 또는 프로세스에게 주어진 time이 끝나 timer interrupt가 발생하면 ready로 온다.
waiting : I/O요청이 왔을 때나 이벤트를 기다릴 때만 이쪽으로 옴. I/O완료나 이벤트 완료를기다리는 상태. 끝나면 ready로 간다.
terminated : 프로세스가 종료됨.
Process Control Block(PCB)
아~주 많은 프로세스들이 동작하기 때문에 이들을 관리하기 위해서 PCB가 있다.
커널에서 관리되고 있는 프로세스의 모든 정보를 가지고 있는 구조체. 한 프로세스에 하나씩.

PCB는 이렇게 구성되어있다.
Process state : 프로세스의 상태
Process number
Program counter : 어디까지 했는지를 저장. 프로세스에서 다음에 실행할 명령어의 주소
CPU register : 실행할 명령어를 수행하는 데 어떤 값들을 사용해서 연산할 것인지를 저장, 프로그램 카운터와 함께 다시 로드됐을 때 스케줄링할 때 필요
CPU scheduling information : CPU 스케줄링을 위한 정보.
Memory-management information
Accounting information : 멀티 유저 환경에서 필요한 정보
I/O status information : 연결되어 있는 I/O 장치에 대한 정보
등등
리눅스 2.4.18 기준 1456bytes만큼 차지한다. 데이터 많다!
Context Switch (CPU Switch)
컴퓨터의 멀티태스킹을 위해 두 가지 프로세스를 빠르게 번갈아가며 수행하기 위해서 필요한 것이 바로 Context switching. 일반적으로 초당 100 or 1000번 정도 발생한다.

현재 프로세스가 실행중일 때 인터럽트나 시스템 콜이 들어오면 PCB에 현재 프로세스의 정보(문맥)들을 저장하고, 다른 프로세스의 정보가 저장되어 있는 PCB에서 정보를 CPU에 로드하여 수행. 그 후 일이 끝나면 CPU의 레지스터 정보를 현재 프로세스의 PCB에 복사 후 다시 원래 프로세스의 PCB에서 정보를 불러와 CPU에 로드한 후 원래 프로세스를 다시 수행.
단점: 무조건 오버헤드임. Context switch하는 동안에는 달리 유의미한 행동을 하지 않기 때문. Context switch할 때 하는 작업들(pcb에 정보를 저장하고, 꺼내는 것) 자체가 오버헤드다.
Long-term scheduler (or job scheduler)
실행해야 하는 프로세스들이 많을 때 어떤 프로세스를 메모리에 올려줄지를 고르는 스케줄러.
ex) 메모리가 8G밖에 안되고, 내가 실행하고 싶은 프로그램이 1.5G일 때, 운영체제가 쓰는 1GB빼고 7GB의 공간에는 4개의 프로그램이 올라간다. 어떤 프로그램을 메모리에 올릴 것인가...
Short-term scheduler
레디 큐에 있는 프로세스들 중에서 어떤 녀석을 CPU에 올려줄 것인지를 고르는 스케줄러.
Medium-term scheduler
쓰다보니 메모리에 올라간 프로그램이 점점 메모리를 많이 먹게 될때는 메모리에 있는 프로세스중 하나를 내려야 한다. 이를 처리하는 것이 Medium-term scheduler이다.

디스크에서 메모리로 올리는 것이 swap in, 그 반대가 swap out.
프로세스는 PCB로 관리되는데, PCB들은 레디 큐 안에 로 doubly-linked-list로 연결이 되어 있다. CPU에서 바로 레디 큐로 돌아갈 수도 있지만, 대기 큐로 가는 경우도 있다. (I/O 요청이 있을 때) 이 때 대기 큐에서도 PCB들이 똑같이 doubly-linked-list로 연결이 되어 있다.


Operation on Processes
POSIX
Process creation : fork()
Process execution : exec()
Process termination : exit(), _exit(), abort(), wait()
Cooperating processes : Inter-Process Communication(IPC)
exit() : 프로세스가 종료되기 위한 여러 사후처리를 한 뒤에 종료, 이 안에서 _exit()역시 호출함.
_exit() : 그냥 종료, 사후처리같은건 없다!
abort() : 비정상적으로 종료된, 뭔가 잘못된 상황에 활용됨. 오류 코드를 보고하며 이 안에서도 _exit()을 호출함. 일반 프 로그램에서는 사용하지 않고, 경우에 따라 라이브러리 구현에 사용된다.
return from main() : 정상 종료, 메인 함수의 끝.
wait() : 자식 프로세스가 끝날 떄까지 기다림. 만약 부모가 wait하지 않으면 자식 프로세스가 zombie상태가 되고 invoking wait없이 부모가 종료되면 자식 프로세스가 orphan상태가 됨.
int fork(): int를 반환하는 함수형 시스템 콜.
- PCB를 만들고 초기화함
- 새로운 메모리 공간을 만들고 초기화함
- 부모와 완전 같은 정보를 복사한 자식을 만들고 자식 PCB를 레디 큐에 넣는다.
- 부모의 fork()가 끝나면 자식의 PID를 반환하고, 자식의 fork()가 끝나면 정수값 0이 반환된다.
fork()는 부모와 자식이 협력해서 무언가를 처리할 때 아주 유용함.
int exec(char *prog, char *argv[]): 보통 fork()와 같이 실행됨, prog을 메모리 위에 올려서 실행해줘!
- 현재 프로세스를 멈춘다.
- prog을 메모리 주소로 로드한다. (prog는 프로그램)
- 하드웨어 문맥과 새로운 프로그램에 필요한 인수들을 집어넣고 초기화함.
- 새로운 프로그램을 로드한 이 프로세스는 실행 가능한 상태가 됬으니 레디 큐에 집어 넣음.
*exec()은 새로운 프로세스를 생성하는 것이 아니라 지금 exec()하고 있는 프로세스에 새로운 프로그램을 덮어쓰는 것. 따라서 일반적으로 fork()->exec()임.

WINDOWS
Creation/Execution
bool CreateProcess()char *prog, char *args,...) --> fork() + exec()
Inter Process Communication (IPC)
프로세스가 다른 프로세스와 데이터를 공유하면 협력적(cooperating), 그렇지 않으면 독립적(independent)라고 한다.
프로세스간 협력은 필요한데, 그 이유를 세 가지 들어보면 :
1. Information sharing : 여러 어플리케이션이 같은 정보를 사용하거나 동시에 접근할 수 있는 방법을 제공해야 한다.
2. Computation speedup : 멀티코어의 경우 특정 작업을 빠르게 처리하기 위해서 병렬적으로 처리함.
3. Modularity: 시스템 함수들을 분리된 프로세스나 스레드로 나눔
프로세스간의 협력에는 IPC가 있어야한다. IPC에는 두 가지 커뮤니케이션 모델이 있는데, Message passing과 Shared memory가 있다. 대부분의 운영체제에서 둘 다 구현이 되어있다.
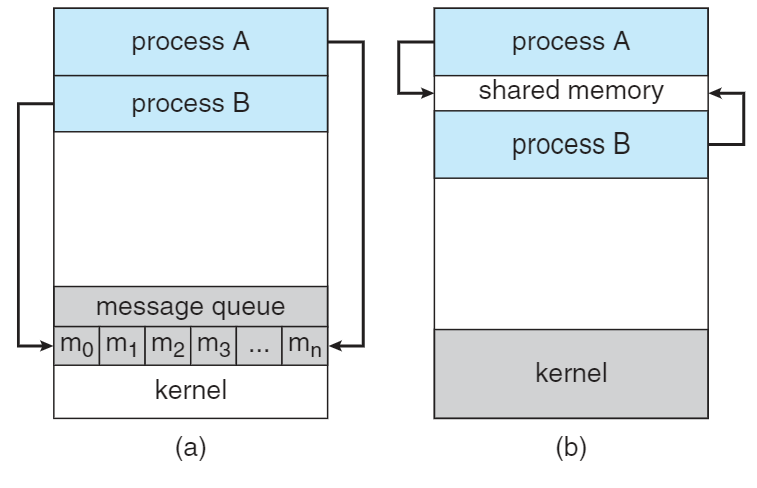
Message passing : 작은 데이터를 주고받을 때 유용하다. 또한 shared memory처럼 두 프로세스가 메모리에 붙어있을 필요가 없음므로 분산 체계의 경우 구현하기 좋다. 시스템 콜을 사용하기 때문에 커널과 함께 작업하므로 shared memory에 비해 시간이 더 걸린다.
Shared memory : Message passing보다는 빠르다. shared memory를 만들면 시스템 호출할 일이 없다.
댓글